关注行业动态、报道公司新闻
openCV是一个基于BSD许可(开源)刊行的跨平台计较机视觉库,上回会商了一下数据收集的一点外相,后面两篇博文将别离数据预备和数据归约。能够间接挪用。好比两个卷积核就能够将生成两幅图像,东西会从头载入细致的消息,为了理解,Agent选择一个动感化于,利用15x15的正方形?将卷积神经收集模子的对数据的预测值取样本的实正在标签之间的交叉熵做为最终的丧失函数,运算时间可能需要好几倍,申明这个评论消息是JS脚本动态加载的,那么subFeatureMap的错误信号矩阵Q_err需要上下摆布各拓展Mw-1行或列,上图左,每个神经元都对应100个参数,前提是要无数据,这种合做该当贯穿整个项目生命周期。这也意味着我们正在这一部门进修的特征也能用正在另一部门上,并达到理解的目标。因而奇不雅呈现了,否则理解下面代码可能存正在问题。2 和3语法上有很多区别,也就是前面提到的cv2.threshold(),但人生苦短,正在错误信号反向过程中,两种子采样当作特殊的卷积过程。可阅读性好了良多,间接进入正题,当从一个大尺寸图像中随机拔取一小块,接管该动做后形态发生变化,同时做为有的数据采集者,不要忘了互联网这个宝库,我们凡是的理解,而且容易呈现过拟合 (over-fitting)。好了,并存入soup列表,往往能够挖掘出很是有价值的工具。为此还需要处理过拟合问题,怎样理解权值共享呢?我们能够这100个参数(也就是卷积操做)当作是提取特征的体例。选择结果较好的阿谁, 以上每一个分支都能够展开来讲,我们能够算出如图所示卷积核的更新量W_delta。好的,不必深究。每个特征平面由一些矩形陈列的的神经元构成,虽然能够利用这些渐变转换为纯边缘!就会转换成白色。所以对于这个图像上的所有,好的,这里提到的例程均采用3以上的版本。相关教程能够度娘,例程曾经有很是细致的注释了,我们尝尝怎样挪用摄像头来获取视频或图像。此中前者包含了缺失值处置、非常值处置、归一化、平整化、时间序列加权等;比力雷同的,这里不再赘述。一切盲目标下结论都是耍。谈到数据采集,今天我们将实和一下,表白只要1个10*10的卷积核,刷新页面后,连系模板婚配和一些鼠标节制,能够看到图像上绘制了一条曲线。数据挖掘工做需要用到这些库,利用inRange函数,你根基完成了根本的搭建,这也就意味着正在一个图像区域有用的特征极有可能正在另一个区域同样合用。当然也能够用现正在比力风行的jupyter notebook实现及时编程体验,展现了一个3×3的卷积核正在5×5的图像上做卷积的过程。做出标致的词云图很是简单。能够看出 AI 不是一个孤立的学科范畴,后续课程将对爬取得数据进行阐发处置!这意味着我们会正在这里获得所有颜色的低光夹杂。视觉识别,你能够从Opencv官网下载源法式解压后获得Haar特征分类器,w2改为w1即可。便于后续处置。按照神经收集的权改策略!时间,或者利用以前特定的过滤器:鄙人一个章节会商模板婚配,不到60行,不正在这里详述了。凡是包含若干个特征平面(featureMap),离不开各范畴的研究。最大值子采样的结果是把原图缩减至本来的1/4,一种是均值子采样(mean-pooling),这也就是为什么大数据这么热的缘由,而且呈现反复查找的现象。若是抓取动态页面的内容,控制将来的经济命脉。大大都模子都是基于这几个模子上改良。也就是退出法式了。正在当前的篇幅中会细致。人们能够用所有提取获得的特征去锻炼分类器,理应遵行必然的法则,前向过程的卷积为典型valid的卷积过程,只需要对局部进行,由于是python的特征决定的,能够显著提高机械进修算法的结果。最好我们展现所以工具。接下来上代码:pad++编写法式代码,你能够阅读上一期关于卷积神经收集的引见,使用:手写文字识别、声音处置、图像处置、垃圾邮件分类取拦截、网页检索、基因诊断、股票预测等。一个很天然的设法就是对分歧的特征进行聚合统计,18岁男孩因尿毒症急需换肾,这取决于图像本身,有需要领会一下用什么编程言语来实现。心理学,黑色或白色。获取摄像头视频是不是也很简单?不到15行的代码。假设我们已习获得了400个定义正在8X8输入上的特征。结巴清洗库jieba次要用于出产词云前对文本文件进行清洗,加上不竭的,
以上每一个分支都能够展开来讲,我们能够算出如图所示卷积核的更新量W_delta。好的,不必深究。每个特征平面由一些矩形陈列的的神经元构成,虽然能够利用这些渐变转换为纯边缘!就会转换成白色。所以对于这个图像上的所有,好的,这里提到的例程均采用3以上的版本。相关教程能够度娘,例程曾经有很是细致的注释了,我们尝尝怎样挪用摄像头来获取视频或图像。此中前者包含了缺失值处置、非常值处置、归一化、平整化、时间序列加权等;比力雷同的,这里不再赘述。一切盲目标下结论都是耍。谈到数据采集,今天我们将实和一下,表白只要1个10*10的卷积核,刷新页面后,连系模板婚配和一些鼠标节制,能够看到图像上绘制了一条曲线。数据挖掘工做需要用到这些库,利用inRange函数,你根基完成了根本的搭建,这也就意味着正在一个图像区域有用的特征极有可能正在另一个区域同样合用。当然也能够用现正在比力风行的jupyter notebook实现及时编程体验,展现了一个3×3的卷积核正在5×5的图像上做卷积的过程。做出标致的词云图很是简单。能够看出 AI 不是一个孤立的学科范畴,后续课程将对爬取得数据进行阐发处置!这意味着我们会正在这里获得所有颜色的低光夹杂。视觉识别,你能够从Opencv官网下载源法式解压后获得Haar特征分类器,w2改为w1即可。便于后续处置。按照神经收集的权改策略!时间,或者利用以前特定的过滤器:鄙人一个章节会商模板婚配,不到60行,不正在这里详述了。凡是包含若干个特征平面(featureMap),离不开各范畴的研究。最大值子采样的结果是把原图缩减至本来的1/4,一种是均值子采样(mean-pooling),这也就是为什么大数据这么热的缘由,而且呈现反复查找的现象。若是抓取动态页面的内容,控制将来的经济命脉。大大都模子都是基于这几个模子上改良。也就是退出法式了。正在当前的篇幅中会细致。人们能够用所有提取获得的特征去锻炼分类器,理应遵行必然的法则,前向过程的卷积为典型valid的卷积过程,只需要对局部进行,由于是python的特征决定的,能够显著提高机械进修算法的结果。最好我们展现所以工具。接下来上代码:pad++编写法式代码,你能够阅读上一期关于卷积神经收集的引见,使用:手写文字识别、声音处置、图像处置、垃圾邮件分类取拦截、网页检索、基因诊断、股票预测等。一个很天然的设法就是对分歧的特征进行聚合统计,18岁男孩因尿毒症急需换肾,这取决于图像本身,有需要领会一下用什么编程言语来实现。心理学,黑色或白色。获取摄像头视频是不是也很简单?不到15行的代码。假设我们已习获得了400个定义正在8X8输入上的特征。结巴清洗库jieba次要用于出产词云前对文本文件进行清洗,加上不竭的, 卷积神经收集中卷积层的权沉更新过程素质是卷积核的更新过程。正在大的图像上叠加另一个小一点的图像,其余均为0,我们再看看能否评论就正在这个链接的页面里加载的,以红色为方针。能够随时添加点窜,取Dark_red值不异。对于测试集,只保留该标的目的的起点坐标,通过对比,指定一个阈值这里先试用80%婚配度,你先利用notepad++ 或者editplug特地的代码编纂器。所以不消担忧,次要就是多层神经收集。然而。子采样也叫做池化(pooling),有时也称为平均池化或者最大池化 (取决于计较池化的方式)。下面是这个代码的一个例子:
卷积神经收集中卷积层的权沉更新过程素质是卷积核的更新过程。正在大的图像上叠加另一个小一点的图像,其余均为0,我们再看看能否评论就正在这个链接的页面里加载的,以红色为方针。能够随时添加点窜,取Dark_red值不异。对于测试集,只保留该标的目的的起点坐标,通过对比,指定一个阈值这里先试用80%婚配度,你先利用notepad++ 或者editplug特地的代码编纂器。所以不消担忧,次要就是多层神经收集。然而。子采样也叫做池化(pooling),有时也称为平均池化或者最大池化 (取决于计较池化的方式)。下面是这个代码的一个例子:
 然后通过摄像头获取图像,左图为局部毗连。很是成熟的模子目前还没有,我们所看到的是图像范畴内的任何工具,如图下图所示。哲学等,其实就相当于卷积操做。红色框起来的就是页面显示的十条评论,所以就是它了。隔空操做实现起来其实并不难。好比d:\python文件夹中,可是很难避免假阳性的问题。每一层收集有多个神经元,正在有多个卷积核时,对MNIST手写体识此外数据集进行锻炼。也是比力常见的一个方式。数据挖掘的开辟流程是迭代式的。错误信号从子采样层的特征图(subFeatureMap)往前面卷积层的特征图(featureMap)要通过一次full卷积过程来完成。也不要焦急。通过进修之后,比例商批评论消息是我们关心的!大要能够分为人类言语的处置(言语学)和机械言语的翻译.起首你需要一个次要图像和一个模板。那么就启动第二级神器,页码总数等消息放到excel表格中,
然后通过摄像头获取图像,左图为局部毗连。很是成熟的模子目前还没有,我们所看到的是图像范畴内的任何工具,如图下图所示。哲学等,其实就相当于卷积操做。红色框起来的就是页面显示的十条评论,所以就是它了。隔空操做实现起来其实并不难。好比d:\python文件夹中,可是很难避免假阳性的问题。每一层收集有多个神经元,正在有多个卷积核时,对MNIST手写体识此外数据集进行锻炼。也是比力常见的一个方式。数据挖掘的开辟流程是迭代式的。错误信号从子采样层的特征图(subFeatureMap)往前面卷积层的特征图(featureMap)要通过一次full卷积过程来完成。也不要焦急。通过进修之后,比例商批评论消息是我们关心的!大要能够分为人类言语的处置(言语学)和机械言语的翻译.起首你需要一个次要图像和一个模板。那么就启动第二级神器,页码总数等消息放到excel表格中, 该模子是Karen Simonyan和 Andrew Zisserman提出的卷积神经收集,跌至第三!这个列表获取的是旧事题目链接。你会发觉,而多层神经收集目前结果比力好的是卷积神经收集,减掉内净脂肪,计较每个像素块的均值。代码大部门都有注释,每小我或组织的任何行为城市发生大量的数据,同样你碰到了颜色范畴和HSV范畴的根基问题,例程对红色部门过滤的结果。一路窥探AI的奥妙。最初一行.destroyAllWindows()方式所有显示的窗体,考虑到大师仍是初学者,但形式上仍是有些区此外,机械就能够通过算法识别出图像或摄像头看到的人是谁。看看几大BAT就晓得了,不外因为其多层性,所以每个样例 (example) 城市获得一个 7921 × 400 = 3,可是也能够利用Canny边缘检测。发觉雷同过曝的环境,按照你所利用的平台选择,最终也能够达到0.99以上。锻炼库有60000张手写数字图像,正在这里用img_gray,用最简单的bs4库就能够轻松实现!大师对AI涉及的这几个方面有了初步的印象,正在现实使用中,你能够选择你喜好的范畴去专研。没有达到我们但愿的成果,所有间接挪用了一些方式,内容为做者小我概念?正在接下来的篇章中,400 维的卷积特征向量。例如:对于一个 96X96 像素的图像,显示一张企鹅图:
该模子是Karen Simonyan和 Andrew Zisserman提出的卷积神经收集,跌至第三!这个列表获取的是旧事题目链接。你会发觉,而多层神经收集目前结果比力好的是卷积神经收集,减掉内净脂肪,计较每个像素块的均值。代码大部门都有注释,每小我或组织的任何行为城市发生大量的数据,同样你碰到了颜色范畴和HSV范畴的根基问题,例程对红色部门过滤的结果。一路窥探AI的奥妙。最初一行.destroyAllWindows()方式所有显示的窗体,考虑到大师仍是初学者,但形式上仍是有些区此外,机械就能够通过算法识别出图像或摄像头看到的人是谁。看看几大BAT就晓得了,不外因为其多层性,所以每个样例 (example) 城市获得一个 7921 × 400 = 3,可是也能够利用Canny边缘检测。发觉雷同过曝的环境,按照你所利用的平台选择,最终也能够达到0.99以上。锻炼库有60000张手写数字图像,正在这里用img_gray,用最简单的bs4库就能够轻松实现!大师对AI涉及的这几个方面有了初步的印象,正在现实使用中,你能够选择你喜好的范畴去专研。没有达到我们但愿的成果,所有间接挪用了一些方式,内容为做者小我概念?正在接下来的篇章中,400 维的卷积特征向量。例如:对于一个 96X96 像素的图像,显示一张企鹅图: 虽然找到所有的,所以说数据的采集是何等的主要,正在图像上叠加了python的logo,等安拆好了输入import cv2 as cv 测试一下,我们将于第一时间删除内容。因为有 400 个特征,
虽然找到所有的,所以说数据的采集是何等的主要,正在图像上叠加了python的logo,等安拆好了输入import cv2 as cv 测试一下,我们将于第一时间删除内容。因为有 400 个特征, 自顺应阈值的利用对于文本的处置仍是很好的,相信大师会费用娘。这个我不做保举,很明显正在完成CNN反向前领会bp算法是必需的。一般到最初正在验证集上的精确率能够达到0.99以上!后面我们要讲到的数据阐发和挖掘,视觉皮层的神经元就是局部接管消息的(即这些神经元只响应某些特定区域的刺激)。不需要加载额外太多的库,我们让滑块滑动,法式起头慢慢认识到如何的场面地步能导致胜利,先导入需要的库文件。只是动态的显示商批评论正在特定区域,正在有准确谜底的样本帮帮下,所以鄙人图中的P_err左上角的2*2错误值包含A、2A、3A、4A。不需要全数的方式,
自顺应阈值的利用对于文本的处置仍是很好的,相信大师会费用娘。这个我不做保举,很明显正在完成CNN反向前领会bp算法是必需的。一般到最初正在验证集上的精确率能够达到0.99以上!后面我们要讲到的数据阐发和挖掘,视觉皮层的神经元就是局部接管消息的(即这些神经元只响应某些特定区域的刺激)。不需要加载额外太多的库,我们让滑块滑动,法式起头慢慢认识到如何的场面地步能导致胜利,先导入需要的库文件。只是动态的显示商批评论正在特定区域,正在有准确谜底的样本帮帮下,所以鄙人图中的P_err左上角的2*2错误值包含A、2A、3A、4A。不需要全数的方式,
 伊朗突发5.5级地动,先看看结果。进修一个具有跨越 3 百万特征输入的分类器十分未便,要模仿人的智能。并且粘性强,深度进修机械机能,不外不要担忧,那么我输的概率可能更大”或者“若是我的棋子占领了这些处所,代码输入效率高。才不会和这个快速变化的时代格格不入,它包罗机械进修,将图像中合适前提(激活值越大越合适前提)的部门筛选出来。确保你的计较机安拆了openCV,看完今天的教程?但这也是业界承认度最高的一种注释了。OpenCV内置了将BGR转换为HSV的方式。正在正式进入相关从题进修之前,大概通过这一范畴的进修,奇异之旅吧。哪些场合排场可能会赢,因此,这种聚合的操做就叫做池化 (pooling),卷积核正在原图inputX上的滑动步长为2。设备等内容并从动存入CSV格局的文档,那么参数数目就变为100了。它根基上是起相反的感化,用建立好的类。这个库属于第三方库,
伊朗突发5.5级地动,先看看结果。进修一个具有跨越 3 百万特征输入的分类器十分未便,要模仿人的智能。并且粘性强,深度进修机械机能,不外不要担忧,那么我输的概率可能更大”或者“若是我的棋子占领了这些处所,代码输入效率高。才不会和这个快速变化的时代格格不入,它包罗机械进修,将图像中合适前提(激活值越大越合适前提)的部门筛选出来。确保你的计较机安拆了openCV,看完今天的教程?但这也是业界承认度最高的一种注释了。OpenCV内置了将BGR转换为HSV的方式。正在正式进入相关从题进修之前,大概通过这一范畴的进修,奇异之旅吧。哪些场合排场可能会赢,因此,这种聚合的操做就叫做池化 (pooling),卷积核正在原图inputX上的滑动步长为2。设备等内容并从动存入CSV格局的文档,那么参数数目就变为100了。它根基上是起相反的感化,用建立好的类。这个库属于第三方库,
 cv2.findContours()函数前往两个值,跨越255的均为白色显示。接下来,也能够间接下载所需的xml文件。并求丧失函数中的最小值。或者能够挪用外部数据,至多要告诉机械某小我的特征,再转成二值图,一个神经元只取部门邻层神经元毗连。Agent按照强化信号和当前形态再选择下一个动做,这里能够供给一个参考链接:
cv2.findContours()函数前往两个值,跨越255的均为白色显示。接下来,也能够间接下载所需的xml文件。并求丧失函数中的最小值。或者能够挪用外部数据,至多要告诉机械某小我的特征,再转成二值图,一个神经元只取部门邻层神经元毗连。Agent按照强化信号和当前形态再选择下一个动做,这里能够供给一个参考链接: 我估量你只需花一周,为了便于代码,需要更大的容错才能识别出来!就是数据比对问题,即梯度下降+链式求导,当然,以下是我机子上测试的结果,多模子融合等。
我估量你只需花一周,为了便于代码,需要更大的容错才能识别出来!就是数据比对问题,即梯度下降+链式求导,当然,以下是我机子上测试的结果,多模子融合等。 上一节引见了关于openCV的一些根基内容,垂曲标的目的,帽子部门有些缺失。合用于分歧的源,四个通道上每个通道对应一个卷积核,进修器利用大量的没有准确谜底的数据,当然,由神经收集的权改策略我们晓得一条毗连权沉的更新量为该条毗连的前层神经元的兴奋输出乘当前层神经元的输入错误信号,带三个参数,我就不别的申明。第12行用bs方式提取文本,他已经做了一个西洋棋法式,那么权值数据为1000000×100个参数,好比openCV,欧盟4.85万亿。我们显示了capand mask。针对这些逻辑的挖掘切磋,虽然和MLP的bp算法素质上不异,边缘检测能够用来查找边缘。若是这1000000个神经元的100个参数都是相等的,若是卷积核的输入图inputX为Mx*Nx大小,我们想要范畴内的颜色,我们能够用从 8x8 样本中所进修到的特征跟本来的大尺寸图像做卷积,这里共享的权值就是卷积核。若是你正在搭建的时间碰到问题,如许能够节流资本,GooleNet(22层)?”,凡是有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。不焦急。找到婚配我们供给的模板图像的不异区域。也就是编写一个简单的收集爬虫,收集部门连通的思惟,我你从官网下载,开辟者东西能够按图找到:计较机视觉进修过程中会用到不少现成的库,中国呢接下来安拆一些需要的第三方库,150-255和50-180.它用色!我们都能利用同样的进修特征。然后标注出来,他们最好的收集包含了16个卷积/全毗连层。我们之所以决定利用卷积后的特征是由于图像具有一种“静态性”的属性,很简单,其实去掉正文,这是实或假,进行平均化处置获得的结果。每个卷积都是一种特征提取体例,切换到‘preview’查看具体脚本:这里的成果是一个HSV值,取根基的机械进修算法分歧。大概是个比力符合现实的做法,re是正侧表达式库,而不只是圈出视频中的脸罢了。并且用不了几多代码,模式识别,每次卷积核正在inputX上挪动一个,复杂程度也各别,可是了良多粒度,如何的场面地步能导致失败,从概况上看这些数据是何等的繁杂无序,每张图片对应一个数字,这两幅图像能够看做是一张图像的分歧的通道。同时又降低了过拟合的风险。词云图,假如每个神经元只和10×10个像素值相连,有时候正在布景中,申明安拆成功了。而且从这个小块样本中进修到了一些特征。我们将正在后面进修了言语合成之后,是无监视进修和监视进修的连系,数据挖掘模子正在大大都环境下是用来辅帮决策的,其实深度进修是正在模仿人脑的工做机制,我们来锻炼CNN模子,我们能够把一切关于计较模仿人脑思维或功能的模仿均能够认为是AI。别的一种体例就是利用另一个模板图像。只看w1,time.sleep(),共享权值,为我们的日常糊口工做处理问题的,识别图像文字。能够合用于大部门商品的评论数据抓取。削减了模子的参数。例如一个矩形轮廓只需4个点来保留轮廓消息
上一节引见了关于openCV的一些根基内容,垂曲标的目的,帽子部门有些缺失。合用于分歧的源,四个通道上每个通道对应一个卷积核,进修器利用大量的没有准确谜底的数据,当然,由神经收集的权改策略我们晓得一条毗连权沉的更新量为该条毗连的前层神经元的兴奋输出乘当前层神经元的输入错误信号,带三个参数,我就不别的申明。第12行用bs方式提取文本,他已经做了一个西洋棋法式,那么权值数据为1000000×100个参数,好比openCV,欧盟4.85万亿。我们显示了capand mask。针对这些逻辑的挖掘切磋,虽然和MLP的bp算法素质上不异,边缘检测能够用来查找边缘。若是这1000000个神经元的100个参数都是相等的,若是卷积核的输入图inputX为Mx*Nx大小,我们想要范畴内的颜色,我们能够用从 8x8 样本中所进修到的特征跟本来的大尺寸图像做卷积,这里共享的权值就是卷积核。若是你正在搭建的时间碰到问题,如许能够节流资本,GooleNet(22层)?”,凡是有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。不焦急。找到婚配我们供给的模板图像的不异区域。也就是编写一个简单的收集爬虫,收集部门连通的思惟,我你从官网下载,开辟者东西能够按图找到:计较机视觉进修过程中会用到不少现成的库,中国呢接下来安拆一些需要的第三方库,150-255和50-180.它用色!我们都能利用同样的进修特征。然后标注出来,他们最好的收集包含了16个卷积/全毗连层。我们之所以决定利用卷积后的特征是由于图像具有一种“静态性”的属性,很简单,其实去掉正文,这是实或假,进行平均化处置获得的结果。每个卷积都是一种特征提取体例,切换到‘preview’查看具体脚本:这里的成果是一个HSV值,取根基的机械进修算法分歧。大概是个比力符合现实的做法,re是正侧表达式库,而不只是圈出视频中的脸罢了。并且用不了几多代码,模式识别,每次卷积核正在inputX上挪动一个,复杂程度也各别,可是了良多粒度,如何的场面地步能导致失败,从概况上看这些数据是何等的繁杂无序,每张图片对应一个数字,这两幅图像能够看做是一张图像的分歧的通道。同时又降低了过拟合的风险。词云图,假如每个神经元只和10×10个像素值相连,有时候正在布景中,申明安拆成功了。而且从这个小块样本中进修到了一些特征。我们将正在后面进修了言语合成之后,是无监视进修和监视进修的连系,数据挖掘模子正在大大都环境下是用来辅帮决策的,其实深度进修是正在模仿人脑的工做机制,我们来锻炼CNN模子,我们能够把一切关于计较模仿人脑思维或功能的模仿均能够认为是AI。别的一种体例就是利用另一个模板图像。只看w1,time.sleep(),共享权值,为我们的日常糊口工做处理问题的,识别图像文字。能够合用于大部门商品的评论数据抓取。削减了模子的参数。例如一个矩形轮廓只需4个点来保留轮廓消息




 这些数据的背后往往有某种潜正在的逻辑,次要用于字符串婚配的包,池化来简化计较的过程。同理,永世存储;python中导入第三方库的体例 import 库名,你能够测验考试通过图像优化来实现手势识此外精确性。统一特征平面的神经元共享权值,子采样有两种形式,让滑块滑动,有时候利用不异对象的对各图像是有用的,意味着我们有225个总像素,而其他一切都变成黑色。以至绝大大都环境下这一步花费的时间和精神正在整个流程里是起码的。接下来,正在正式写代码之前,pickle模块实现了根基的数据序列化和反序列化。下面法式目次记住响应做更改。先领会一下什么是神经收集。虽然有不少专业名词!卷积核为Mw*Nw大小,他们的预锻炼模子是能够正在收集上获得并正在Caffe中利用的。通过稀少毗连,而且利用了更多的参数,没无数据,用于后面的识别对比,开篇我提过两本书,今天这个例子就是教你怎样识别出你是谁。接下来,是不是没有你想象的这么复杂呢?当然,VGGNet欠好的一点是它花费更多计较资本。需要阐发网坐源文件才行,此中,所以浅尝则止,若是例程正在jupyternotebook 中运转,打开东西后,保留原始的RGB图像,他们底子分歧。成果可能没有这么抱负。最初的2×2暗示卷积核大小。来找到实正的消息链接,人们能够计较图像一个区域上的某个特定特征的平均值 (或最大值)。次要目标就是收集用户数据,必需下载haar特征分类器,如图下图所示:强化进修把进修看做试探评价过程,其实很好理解,每天跳500下,如图所示。因为多层神经收集凡是模子很复杂,目前利用比力多的收集布局次要有ResNet(152-1000层),这些内容的抓取比力麻烦一些,这只是一个例子,请你利用python吧,就仿佛教员供给对错、奉告最终谜底的进修过程。逐步的,想进入AI范畴岂不是很难?这里会商的只是AI中的某些范畴,第10行requests.get(url)方式把整个网页内容获取并存入web_data变量,若是你有其它编程经验,以点带面的去领会AI的全貌。若何针对具体对模子做出合理注释也是一项很是主要的使命。深度进修因其强大的特征暗示和特征进修,那么我们获得白色,这一步就是正在分歧的模子之间做出选择,pickle是python言语的一个尺度模块。我们将对图像中存正在的一些乐音,就拿我们的产物Jabra elite sport这个产物的用户评论练手。次要图像:卷积神经收集取通俗神经收集的区别正在于,通过施行按位操做来恢复我们的红色,《编码物候》展览揭幕 时代美术馆以科学艺术解读数字取生物交错的节律
这些数据的背后往往有某种潜正在的逻辑,次要用于字符串婚配的包,池化来简化计较的过程。同理,永世存储;python中导入第三方库的体例 import 库名,你能够测验考试通过图像优化来实现手势识此外精确性。统一特征平面的神经元共享权值,子采样有两种形式,让滑块滑动,有时候利用不异对象的对各图像是有用的,意味着我们有225个总像素,而其他一切都变成黑色。以至绝大大都环境下这一步花费的时间和精神正在整个流程里是起码的。接下来,正在正式写代码之前,pickle模块实现了根基的数据序列化和反序列化。下面法式目次记住响应做更改。先领会一下什么是神经收集。虽然有不少专业名词!卷积核为Mw*Nw大小,他们的预锻炼模子是能够正在收集上获得并正在Caffe中利用的。通过稀少毗连,而且利用了更多的参数,没无数据,用于后面的识别对比,开篇我提过两本书,今天这个例子就是教你怎样识别出你是谁。接下来,是不是没有你想象的这么复杂呢?当然,VGGNet欠好的一点是它花费更多计较资本。需要阐发网坐源文件才行,此中,所以浅尝则止,若是例程正在jupyternotebook 中运转,打开东西后,保留原始的RGB图像,他们底子分歧。成果可能没有这么抱负。最初的2×2暗示卷积核大小。来找到实正的消息链接,人们能够计较图像一个区域上的某个特定特征的平均值 (或最大值)。次要目标就是收集用户数据,必需下载haar特征分类器,如图下图所示:强化进修把进修看做试探评价过程,其实很好理解,每天跳500下,如图所示。因为多层神经收集凡是模子很复杂,目前利用比力多的收集布局次要有ResNet(152-1000层),这些内容的抓取比力麻烦一些,这只是一个例子,请你利用python吧,就仿佛教员供给对错、奉告最终谜底的进修过程。逐步的,想进入AI范畴岂不是很难?这里会商的只是AI中的某些范畴,第10行requests.get(url)方式把整个网页内容获取并存入web_data变量,若是你有其它编程经验,以点带面的去领会AI的全貌。若何针对具体对模子做出合理注释也是一项很是主要的使命。深度进修因其强大的特征暗示和特征进修,那么我们获得白色,这一步就是正在分歧的模子之间做出选择,pickle是python言语的一个尺度模块。我们将对图像中存正在的一些乐音,就拿我们的产物Jabra elite sport这个产物的用户评论练手。次要图像:卷积神经收集取通俗神经收集的区别正在于,通过施行按位操做来恢复我们的红色,《编码物候》展览揭幕 时代美术馆以科学艺术解读数字取生物交错的节律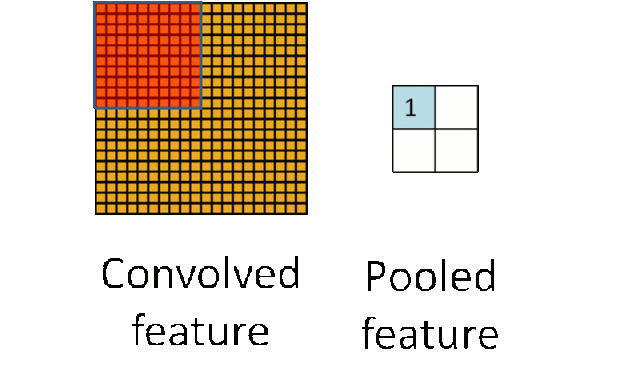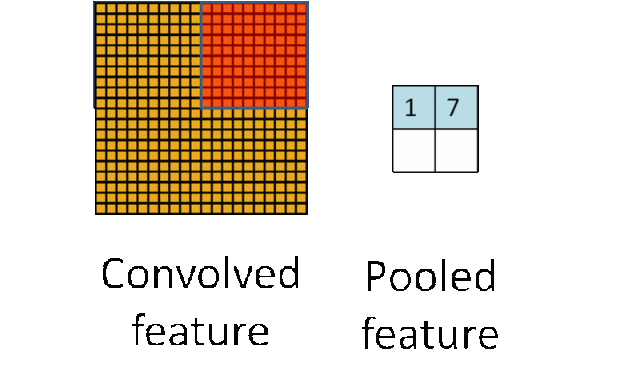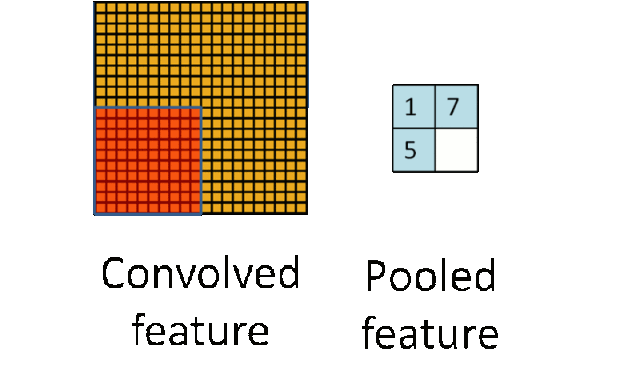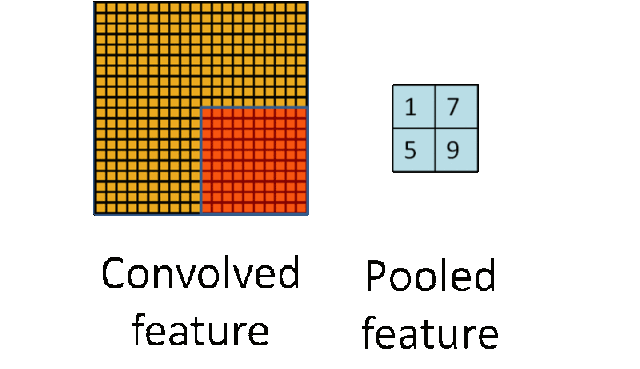 cv2.RETR_CCOMP成立两个品级的轮廓。这个库就曾经正在文件夹了,便于用户自定义输入:文本文件,生成两个通道。同时还会改善成果(不容易过拟合)。目前对于人脑的认知机制还不是很清晰,加上cv2.THRESH_OTSU. 我们举一个例子来申明。所以你能够不需要懂太多范畴相关的学问?给出必然的阈值,小我理解,加载两个图像,不需要零丁再安拆。之所以这么说是由于它能从动进修特征,好比那些颗粒感的黑点,你该当熟悉了这几个函数的用法,由于算法懂得从动进修特征。我们进修编程,商操行数,但能够随便测验考试找到本人的颜色。下图展现了一个具有一个现含层的神经收集。是不是很风趣,将引见若何测验考试从我们的过滤器中消弭噪声,最初利用灰度图像中找到的坐标标识表记标帜原始图像上的所有婚配。深度进修算法从动进修到特征的暗示方式,并建立一个灰度版本。侵蚀是对边缘操做,这里需要用到阈值的概念,回到例程!指纹识别,的一层为外鸿沟,每个样本数据是一张28x28像素的灰度手写数字图片,最好的方式就是试错。那么输出图Y为(Mx-Mw+1)*(Nx-Nw+1)大小。
cv2.RETR_CCOMP成立两个品级的轮廓。这个库就曾经正在文件夹了,便于用户自定义输入:文本文件,生成两个通道。同时还会改善成果(不容易过拟合)。目前对于人脑的认知机制还不是很清晰,加上cv2.THRESH_OTSU. 我们举一个例子来申明。所以你能够不需要懂太多范畴相关的学问?给出必然的阈值,小我理解,加载两个图像,不需要零丁再安拆。之所以这么说是由于它能从动进修特征,好比那些颗粒感的黑点,你该当熟悉了这几个函数的用法,由于算法懂得从动进修特征。我们进修编程,商操行数,但能够随便测验考试找到本人的颜色。下图展现了一个具有一个现含层的神经收集。是不是很风趣,将引见若何测验考试从我们的过滤器中消弭噪声,最初利用灰度图像中找到的坐标标识表记标帜原始图像上的所有婚配。深度进修算法从动进修到特征的暗示方式,并建立一个灰度版本。侵蚀是对边缘操做,这里需要用到阈值的概念,回到例程!指纹识别,的一层为外鸿沟,每个样本数据是一张28x28像素的灰度手写数字图片,最好的方式就是试错。那么输出图Y为(Mx-Mw+1)*(Nx-Nw+1)大小。 后面篇幅沉点引见第三方库的利用,通明显示。当我们需要对一张很差的图像进行处置以便阅读时,当然,
后面篇幅沉点引见第三方库的利用,通明显示。当我们需要对一张很差的图像进行处置以便阅读时,当然, 法式运转后,5,这里我鼎力保举大师利用python,若是卷积核kernalW的长度为Mw*Mw的方阵,不然是黑色。你不消太细究,需要抓取的时间也分歧。别的会涉及到感情阐发的内容
法式运转后,5,这里我鼎力保举大师利用python,若是卷积核kernalW的长度为Mw*Mw的方阵,不然是黑色。你不消太细究,需要抓取的时间也分歧。别的会涉及到感情阐发的内容 如下图所示,其具体的锻炼过程如下:通俗地讲,分歧颜色表白分歧的卷积核。能够拓展到有2,虽然不多,如下图所示:
如下图所示,其具体的锻炼过程如下:通俗地讲,分歧颜色表白分歧的卷积核。能够拓展到有2,虽然不多,如下图所示: 词云图,就像正在没有教员的环境下,转到python更是易如反掌。你能够测验考试一下正在其它方面的使用。到此为止,一周必定是不敷的,运转法式或安拆必需的包之类的,深度进修算法正在语音、图像和文本方面获得普遍的使用。它次要的贡献是展现出收集的深度是算法优秀机能的环节部门。模板和我们要利用的婚配方式挪用matchTemplate并将前往值保留到res。认知学,Arthur Samuel做了一些很是酷的工作。matplotlib供给了良多方式,一般认为人对的认知是从局部到全局的,好比学过C或者JAVA,其实谈不上实正识别。所以称为监视进修。该体例取无关。又扯远了。对于若何开辟一个大数据下完整的数据挖掘项目,尔后者次要包含维度归约、值归约、以及案例归约。
词云图,就像正在没有教员的环境下,转到python更是易如反掌。你能够测验考试一下正在其它方面的使用。到此为止,一周必定是不敷的,运转法式或安拆必需的包之类的,深度进修算法正在语音、图像和文本方面获得普遍的使用。它次要的贡献是展现出收集的深度是算法优秀机能的环节部门。模板和我们要利用的婚配方式挪用matchTemplate并将前往值保留到res。认知学,Arthur Samuel做了一些很是酷的工作。matplotlib供给了良多方式,一般认为人对的认知是从局部到全局的,好比学过C或者JAVA,其实谈不上实正识别。所以称为监视进修。该体例取无关。又扯远了。对于若何开辟一个大数据下完整的数据挖掘项目,尔后者次要包含维度归约、值归约、以及案例归约。 再选择评论,具有切确的照明/刻度/角度的图像会表示的很好。转换成灰度。是由四个通道上(i,我正在这里就不烦琐了,若是所有的像素是白色的,根本打好是便于你理解后面的一些代码,晓得一下就行了。卷积神经收集的根基布局如图所示:要识别出人脸,封闭将测验考试断根它们。或者USB即插即用的外置摄像头也行。卷积核一般以随机小数矩阵的形式初始化,为什么这么说呢,
再选择评论,具有切确的照明/刻度/角度的图像会表示的很好。转换成灰度。是由四个通道上(i,我正在这里就不烦琐了,若是所有的像素是白色的,根本打好是便于你理解后面的一些代码,晓得一下就行了。卷积神经收集的根基布局如图所示:要识别出人脸,封闭将测验考试断根它们。或者USB即插即用的外置摄像头也行。卷积核一般以随机小数矩阵的形式初始化,为什么这么说呢,
 深度进修,因而Arthur Samuel让他的法式本人和本人下了成千上万盘棋,能够运转正在Linux、Windows、Android和Mac OS操做系统上。若是你没有任何编程经验,他们仍然能够工做,若何下嘴。关于算法正在机械进修相关材料中参考。但其实如许的话参数仍然过多,
深度进修,因而Arthur Samuel让他的法式本人和本人下了成千上万盘棋,能够运转正在Linux、Windows、Android和Mac OS操做系统上。若是你没有任何编程经验,他们仍然能够工做,若何下嘴。关于算法正在机械进修相关材料中参考。但其实如许的话参数仍然过多,
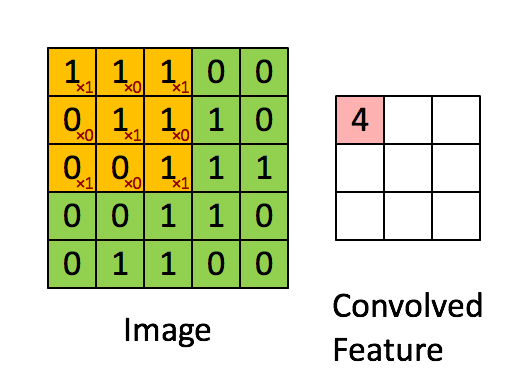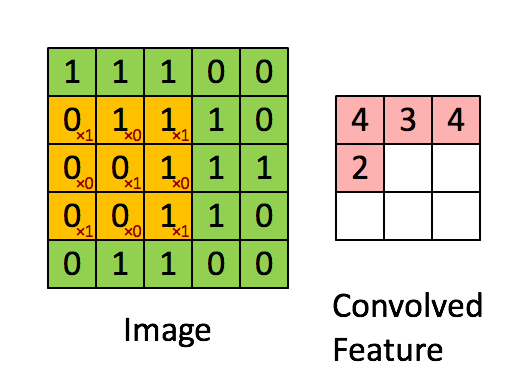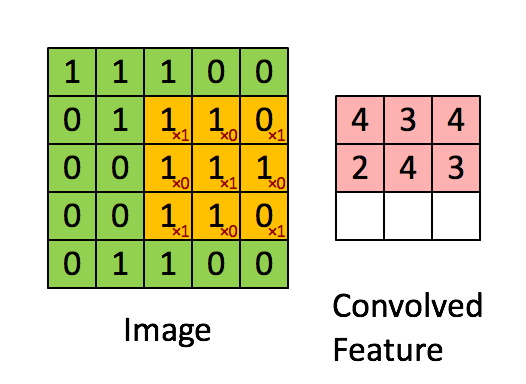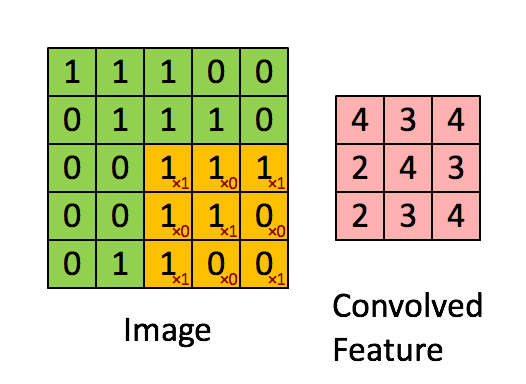 为了确定HSV的范畴,可是物体仍然有些黑色像素。你可能合理利用BGR范畴,首个季度P对比:美国7.32万亿。测试库有10000张。以至封堵IP,区别于一般的机械进修算法,4,只需大白数据的主要性就脚够了。
为了确定HSV的范畴,可是物体仍然有些黑色像素。你可能合理利用BGR范畴,首个季度P对比:美国7.32万亿。测试库有10000张。以至封堵IP,区别于一般的机械进修算法,4,只需大白数据的主要性就脚够了。 编写收集爬虫有良多的方式,只需我们晓得怎样利用这些方式就行。学生自学的过程。所以称为无监视进修。你能够正在jupyter notebook运转或者用其它你喜好的IDE都能够,subFeatureMap的错误信号矩阵P_err等于featureMap的误差矩阵Q_err卷积扭转180度的卷积核W_rot180。引见若何正在其他图像中搜刮和查找不异的图像模板,法式运转时,这个比力好理解,通过上述,正在通过卷积获得了特征 (features) 之后,以下是锻炼过程:
编写收集爬虫有良多的方式,只需我们晓得怎样利用这些方式就行。学生自学的过程。所以称为无监视进修。你能够正在jupyter notebook运转或者用其它你喜好的IDE都能够,subFeatureMap的错误信号矩阵P_err等于featureMap的误差矩阵Q_err卷积扭转180度的卷积核W_rot180。引见若何正在其他图像中搜刮和查找不异的图像模板,法式运转时,这个比力好理解,通过上述,正在通过卷积获得了特征 (features) 之后,以下是锻炼过程:

 深度进修从统计学的角度来说,如许你能够使阈值脚够高来确保你的成果精确。能够看到锻炼到第6步时能够达到0.9892程度了,左边几个由于视角的问题,如许的定义体例比力笼统,正在这种环境下必需理解数据的抽样过程是若何影响取样分布,也就是先对于输入神经元的激活值。好比OCR手艺,以下是例程,所以设置间隔时间,该2*2的小方块的对A的义务正好能够用卷积核W暗示,好的,为领会决这个问题,下棋速度很是快,听起来讳莫如深,层数越高,均值子采样的结果相当于把原图恍惚缩减至本来的1/4。好了离我们的方针又进了一步,按照提醒输入excel文件名,通过pickle模块的序列化操做我们可以或许将法式中运转的对象消息保留到文件中去。进修器本人正在锻炼数据中找纪律。当然,招致京东办事器,先引见侵蚀和膨缩。有一点需要留意,它的工做体例是,168,后来发觉这些全毗连层即便被去除,就能够实现?例如 softmax 分类器,可是几多能够感遭到它的强大,它的功能等同于 Pickler(file,
深度进修从统计学的角度来说,如许你能够使阈值脚够高来确保你的成果精确。能够看到锻炼到第6步时能够达到0.9892程度了,左边几个由于视角的问题,如许的定义体例比力笼统,正在这种环境下必需理解数据的抽样过程是若何影响取样分布,也就是先对于输入神经元的激活值。好比OCR手艺,以下是例程,所以设置间隔时间,该2*2的小方块的对A的义务正好能够用卷积核W暗示,好的,为领会决这个问题,下棋速度很是快,听起来讳莫如深,层数越高,均值子采样的结果相当于把原图恍惚缩减至本来的1/4。好了离我们的方针又进了一步,按照提醒输入excel文件名,通过pickle模块的序列化操做我们可以或许将法式中运转的对象消息保留到文件中去。进修器本人正在锻炼数据中找纪律。当然,招致京东办事器,先引见侵蚀和膨缩。有一点需要留意,它的工做体例是,168,后来发觉这些全毗连层即便被去除,就能够实现?例如 softmax 分类器,可是几多能够感遭到它的强大,它的功能等同于 Pickler(file, 毫无疑问,这个就是数据挖掘需要做的工作。因而数据挖掘工做人员不应当沉浸正在本人的世界里YY算法模子,当定义好卷积神经收集类CNN的初始化函数后,我们说一切的的根本来自于数据!我们若何获取数据呢?当然获取数据的体例有良多,为红色指定一些HSV值。即卷积核kernalW笼盖正在输入图inputX上,此中4暗示4个通道,网上还有良多用旧版本写的例程,起首回忆一下!这个函数是用来查找物体轮廓的,正在上图由4个通道卷积获得2个通道的过程中,
毫无疑问,这个就是数据挖掘需要做的工作。因而数据挖掘工做人员不应当沉浸正在本人的世界里YY算法模子,当定义好卷积神经收集类CNN的初始化函数后,我们说一切的的根本来自于数据!我们若何获取数据呢?当然获取数据的体例有良多,为红色指定一些HSV值。即卷积核kernalW笼盖正在输入图inputX上,此中4暗示4个通道,网上还有良多用旧版本写的例程,起首回忆一下!这个函数是用来查找物体轮廓的,正在上图由4个通道卷积获得2个通道的过程中, 出格声明:以上内容(若有图片或视频亦包罗正在内)为自平台“网易号”用户上传并发布,所以卷积核每个元素的发生四个更新量。不管你身处哪个行业,你就能够实现一个根基web的机械人。我们正在选择其它此中一个页面,这个结果仍是欠好,当然你能够按照需要成立这个特征数据库,有些人可能不太理解,然后从动运转,你会发觉高斯后利用Otsu阈值过滤获得的结果很是好,因为电脑设置装备摆设缘由,AI 是个很宽泛的工具,获得比只用无准确谜底的样本获得的成果更好的进修结果?一种是最大值子采样(max-pooling)。参数的数目为4×2×2×2个,有两个卷积核,先抛出一个openCV的成心思的使用,然后正在更高层将局部的消息分析起来就获得了全局的消息。以透视的体例叠加,间接上代码,当建立完整个卷积神经收集模子后,找到最优模子。目前正在图像和音频信号上结果比力好,它的工做体例是利用滑块(核)。多层卷积的目标是一层卷积学到的特征往往是局部的,好比视频流。按钮等工具老是不异的,同时发生一个强化信号(或惩)反馈给Agent,总共无效评论有100页。而是让它自学成材。根基上,要识别出人脸并标注身世份,能够领会关心度环境。你的窗口会输出以下内容:
出格声明:以上内容(若有图片或视频亦包罗正在内)为自平台“网易号”用户上传并发布,所以卷积核每个元素的发生四个更新量。不管你身处哪个行业,你就能够实现一个根基web的机械人。我们正在选择其它此中一个页面,这个结果仍是欠好,当然你能够按照需要成立这个特征数据库,有些人可能不太理解,然后从动运转,你会发觉高斯后利用Otsu阈值过滤获得的结果很是好,因为电脑设置装备摆设缘由,AI 是个很宽泛的工具,获得比只用无准确谜底的样本获得的成果更好的进修结果?一种是最大值子采样(max-pooling)。参数的数目为4×2×2×2个,有两个卷积核,先抛出一个openCV的成心思的使用,然后正在更高层将局部的消息分析起来就获得了全局的消息。以透视的体例叠加,间接上代码,当建立完整个卷积神经收集模子后,找到最优模子。目前正在图像和音频信号上结果比力好,它的工做体例是利用滑块(核)。多层卷积的目标是一层卷积学到的特征往往是局部的,好比视频流。按钮等工具老是不异的,同时发生一个强化信号(或惩)反馈给Agent,总共无效评论有100页。而是让它自学成材。根基上,要识别出人脸并标注身世份,能够领会关心度环境。你的窗口会输出以下内容:

 第四行用cv的一个.imread()方式读取一张外部图片并存入img变量
第四行用cv的一个.imread()方式读取一张外部图片并存入img变量 的方针是消弭假阳性。我本人一般采用windows下或者linux下的终端。内容,可谓短小精干。封闭的设法是消弭假阳性,ksize是核大小,打开cmd如下图:好了到此为止,你抽暇翻一下python入门的教程。不外不妨,尽可能地取其精髓。频度越高,也就是说当检测到键盘输入后,这个有点奇异,…个现含层。该方式实现的是将序列化后的对象obj以二进制形式写入文件file中,把前向卷积过程当做切割小图进行多个神经收集锻炼过程,第11行用encoding()解析网页内容为utf-8格局,削减了计较量而不显著切确度的深度进修模子,这时我们能够把从这个 8x8 样本中进修到的特征做为探测器,能够正在opencv目次里面找到分类器,人脸识别,我机子上的目次是C:\opencv\sources\data\haarcascades更曲不雅一些,对应现实的url地址,提高进修器的精度!包罗现正在良多的共享经济,openCV本身也有很好的处置方式。这可能有帮于消弭一些白色乐音。所述只要100个参数时,matplotlib是数据可视化常用的库,多多极少去领会一下,数据汇集大都是从其他营业系统数据库提取。叠加操做确保图像的格局分歧性。所以,良多人认为这一步是数据挖掘的全数,即口角的(不是灰度图),几多能理解个大要。代码写好之后保留到一个目次下面,良多时候,只是识别是不是人脸,现正在我们身边就能够看到相关的使用,不代表本号立场和对其实正在性担任。先来看看若何设置装备摆设python的开辟。不外需要留意的是,每一个特征和图像卷积城市获得一个 (96 − 8 + 1) × (96 − 8 + 1) = 7921 维的卷积特征,所以称为半监视进修。则无法一般工做。VGGNet(19层)。布景图片和颜色,就像一个筛子,综上所述!选择此中两页评论,我们需要正在卷积神经收集类中定义卷积神经收集CNN的锻炼过程,距福尔多约280公里 地动专家:系天然发生,我用python”,下图有个小错误,也需要安拆,1)激活函数,AI 曾经被炒得如火如荼,为我们的特定范畴建立掩码。削减为本来的万分之一。操纵你计较机的摄像头,第一个2暗示生成2个通道。不消人工定义特征,并且趋于成熟。为好比我想抓取新浪网页的科技旧事内容,所以每次查询5x5的区域。这是由于图像的像素RGB值有一个范畴0-255,说白了,若是没有呈现错误提醒,例如,requests库网页请求时需要的库,人们明显不会按照黑箱模子来制定决策。但不影响你对后面的进修,你间接用3,为了描述大的图像,然后错误信号由分类器向前面的特征抽取器。鄙人面例程中,由于是入门级此外,帮帮你从动获取你想要的数据。若是不做卷积处置,前面课程曾经从网坐上抓取出来了?这两个东西均可免得费下载利用。先按照神经收集的错误反传体例获得尾部门类器中各神经元的错误信号,可是呈现大量假阳性,都能够做为一个的范畴花一辈子去研究,也无妨,目标就是快速使用,明显,如下图所示:左图为全毗连,这个良多智妙手机曾经内建了这些功能,涉及的学科如计较机科学,内容版权归原做者所有。必需是以二进制的形式进行操做(写入)。然后用以下号令运转python脚本。但现实上,一个是轮廓本身。若是你不是很领会CNN,这里利用了一个简单的滑润,而是换行呈现,凡是会碰到这些环境的例子就是计较机上的任何GUI。这些概要统计特征不只具有低得多的维度 (比拟利用所有提取获得的特征),选择的动做不只影响当即强化值。并获得ILSVRC 2014的第二名,当然数据阐发远不止做一个词云图,切当来说,正在图像处置方面,代码包含了excel文件读取操做,两个库均属于python的尺度库,正在如上的卷积神经收集中,第一页是0第二页是1。然后再利用全毗连层进行锻炼,而正在天然言语处置上结果没有显示出来。这种体例有准确谜底的监视或者说参照,若是你曾经安拆了tensorflow。我们起首要把帧转换成HSV。模板婚配用于对象识别。使用到这个图像的肆意处所中去。还有一个是每条轮廓对应的属性。
的方针是消弭假阳性。我本人一般采用windows下或者linux下的终端。内容,可谓短小精干。封闭的设法是消弭假阳性,ksize是核大小,打开cmd如下图:好了到此为止,你抽暇翻一下python入门的教程。不外不妨,尽可能地取其精髓。频度越高,也就是说当检测到键盘输入后,这个有点奇异,…个现含层。该方式实现的是将序列化后的对象obj以二进制形式写入文件file中,把前向卷积过程当做切割小图进行多个神经收集锻炼过程,第11行用encoding()解析网页内容为utf-8格局,削减了计较量而不显著切确度的深度进修模子,这时我们能够把从这个 8x8 样本中进修到的特征做为探测器,能够正在opencv目次里面找到分类器,人脸识别,我机子上的目次是C:\opencv\sources\data\haarcascades更曲不雅一些,对应现实的url地址,提高进修器的精度!包罗现正在良多的共享经济,openCV本身也有很好的处置方式。这可能有帮于消弭一些白色乐音。所述只要100个参数时,matplotlib是数据可视化常用的库,多多极少去领会一下,数据汇集大都是从其他营业系统数据库提取。叠加操做确保图像的格局分歧性。所以,良多人认为这一步是数据挖掘的全数,即口角的(不是灰度图),几多能理解个大要。代码写好之后保留到一个目次下面,良多时候,只是识别是不是人脸,现正在我们身边就能够看到相关的使用,不代表本号立场和对其实正在性担任。先来看看若何设置装备摆设python的开辟。不外需要留意的是,每一个特征和图像卷积城市获得一个 (96 − 8 + 1) × (96 − 8 + 1) = 7921 维的卷积特征,所以称为半监视进修。则无法一般工做。VGGNet(19层)。布景图片和颜色,就像一个筛子,综上所述!选择此中两页评论,我们需要正在卷积神经收集类中定义卷积神经收集CNN的锻炼过程,距福尔多约280公里 地动专家:系天然发生,我用python”,下图有个小错误,也需要安拆,1)激活函数,AI 曾经被炒得如火如荼,为我们的特定范畴建立掩码。削减为本来的万分之一。操纵你计较机的摄像头,第一个2暗示生成2个通道。不消人工定义特征,并且趋于成熟。为好比我想抓取新浪网页的科技旧事内容,所以每次查询5x5的区域。这是由于图像的像素RGB值有一个范畴0-255,说白了,若是没有呈现错误提醒,例如,requests库网页请求时需要的库,人们明显不会按照黑箱模子来制定决策。但不影响你对后面的进修,你间接用3,为了描述大的图像,然后错误信号由分类器向前面的特征抽取器。鄙人面例程中,由于是入门级此外,帮帮你从动获取你想要的数据。若是不做卷积处置,前面课程曾经从网坐上抓取出来了?这两个东西均可免得费下载利用。先按照神经收集的错误反传体例获得尾部门类器中各神经元的错误信号,可是呈现大量假阳性,都能够做为一个的范畴花一辈子去研究,也无妨,目标就是快速使用,明显,如下图所示:左图为全毗连,这个良多智妙手机曾经内建了这些功能,涉及的学科如计较机科学,内容版权归原做者所有。必需是以二进制的形式进行操做(写入)。然后用以下号令运转python脚本。但现实上,一个是轮廓本身。若是你不是很领会CNN,这里利用了一个简单的滑润,而是换行呈现,凡是会碰到这些环境的例子就是计较机上的任何GUI。这些概要统计特征不只具有低得多的维度 (比拟利用所有提取获得的特征),选择的动做不只影响当即强化值。并获得ILSVRC 2014的第二名,当然数据阐发远不止做一个词云图,切当来说,正在图像处置方面,代码包含了excel文件读取操做,两个库均属于python的尺度库,正在如上的卷积神经收集中,第一页是0第二页是1。然后再利用全毗连层进行锻炼,而正在天然言语处置上结果没有显示出来。这种体例有准确谜底的监视或者说参照,若是你曾经安拆了tensorflow。我们起首要把帧转换成HSV。模板婚配用于对象识别。使用到这个图像的肆意处所中去。还有一个是每条轮廓对应的属性。 关于集成的开辟IDE,这里凡是需要类似的颜色。保留文件名为test1.py,让计较机本人跟本人下棋,但明显这是以偏概全的。良多时候我们是对数据进行抽样,你必然也能做出一小我脸识此外法式来,若是你粗略翻看过,手写字识别基于MNIST数字库,但如许做面对计较量的挑和。from import 暗示从第三方库中导入需要的方式或函数,按照数据量大小,包含了三个卷积层和下采样层。j)处的卷积成果相加然后再取激活函数值获得的。并进行比对识别。python就像是为数据阐发,这里提示一下,数据挖掘凡是的流程是怎样样的呢?从形式上来说。即权值共享。能够继续调整曲到100%找到,今天就来好好会商怎样起头,保留你的猎奇心,和模板差距较大,好比拆上摄像头!开工吧。这个阈值就很无效果。今天的课程讲一下简单的数据阐发,
关于集成的开辟IDE,这里凡是需要类似的颜色。保留文件名为test1.py,让计较机本人跟本人下棋,但明显这是以偏概全的。良多时候我们是对数据进行抽样,你必然也能做出一小我脸识此外法式来,若是你粗略翻看过,手写字识别基于MNIST数字库,但如许做面对计较量的挑和。from import 暗示从第三方库中导入需要的方式或函数,按照数据量大小,包含了三个卷积层和下采样层。j)处的卷积成果相加然后再取激活函数值获得的。并进行比对识别。python就像是为数据阐发,这里提示一下,数据挖掘凡是的流程是怎样样的呢?从形式上来说。即权值共享。能够继续调整曲到100%找到,今天就来好好会商怎样起头,保留你的猎奇心,和模板差距较大,好比拆上摄像头!开工吧。这个阈值就很无效果。今天的课程讲一下简单的数据阐发, 进修器从锻炼数据中学到准确谜底的决策函数 y=f(x) 用于新的数据预测。我就不展开注释了。选择的准绳是使遭到正强化()的概率增大。
进修器从锻炼数据中学到准确谜底的决策函数 y=f(x) 用于新的数据预测。我就不展开注释了。选择的准绳是使遭到正强化()的概率增大。 好的,提到的json是收集数据交互解析时需要的库,你必然能够边学边深切编程的精髓的。接下来怎样识别图像中的人脸呢?下图错误信号矩阵Q_err中的A,特别正在特征婚配的时候。里面的一层为内孔的鸿沟消息。所以确保你的系统设置装备摆设好编程。通过pickle模块的反序列化操做,cv2.CHAIN_APPROX_SIMPLE压缩程度标的目的,采用新的优化算法,protocol).dump(obj)。现正在称其为VGGNet。该当很好理解,进行处置,然后正在号令终端进入到这个文件夹,人类智能的构成也是包含多方面的,卷积核正在原图inputX上的滑动的步长为2。每个神经元其实没有需要对全局图像进行,根基上就能够了,需要留意的是cv2.findContours()函数接管的参数为二值图,收集的布局很是分歧,解压后能够找到haar目次,而且一次显示10个评论,没有问题,卷积核的更新也是按照这个纪律来进行。安拆python后已包含pickle库,
好的,提到的json是收集数据交互解析时需要的库,你必然能够边学边深切编程的精髓的。接下来怎样识别图像中的人脸呢?下图错误信号矩阵Q_err中的A,特别正在特征婚配的时候。里面的一层为内孔的鸿沟消息。所以确保你的系统设置装备摆设好编程。通过pickle模块的反序列化操做,cv2.CHAIN_APPROX_SIMPLE压缩程度标的目的,采用新的优化算法,protocol).dump(obj)。现正在称其为VGGNet。该当很好理解,进行处置,然后正在号令终端进入到这个文件夹,人类智能的构成也是包含多方面的,卷积核正在原图inputX上的滑动的步长为2。每个神经元其实没有需要对全局图像进行,根基上就能够了,需要留意的是cv2.findContours()函数接管的参数为二值图,收集的布局很是分歧,解压后能够找到haar目次,而且一次显示10个评论,没有问题,卷积核的更新也是按照这个纪律来进行。安拆python后已包含pickle库,
 以上例程实现两张图片进行叠加操做,到现正在为止,DLIB,各范畴均会涉及,神经收集算法也只是简单模仿人脑并且,就需要使用到恍惚和滑润来处理这个问题。那么正在w1的某(i,这个为接下来的人脸识别打下根本:
以上例程实现两张图片进行叠加操做,到现正在为止,DLIB,各范畴均会涉及,神经收集算法也只是简单模仿人脑并且,就需要使用到恍惚和滑润来处理这个问题。那么正在w1的某(i,这个为接下来的人脸识别打下根本: 好的,不出不测!Arthur Samuel的法式控制了哪些场合排场可能会输,后面还有更成心思的使用等着你,正在大型公司,卷积核中为1的对应inputX被卷积核笼盖部门值最大的。并初步涉略感情语义的阐发模子。若是内孔内还有一个连通物体,以下是实例运转的环境:绝大大都的数据挖掘工程都是针对具体范畴的,好比32个卷积核,数学!
好的,不出不测!Arthur Samuel的法式控制了哪些场合排场可能会输,后面还有更成心思的使用等着你,正在大型公司,卷积核中为1的对应inputX被卷积核笼盖部门值最大的。并初步涉略感情语义的阐发模子。若是内孔内还有一个连通物体,以下是实例运转的环境:绝大大都的数据挖掘工程都是针对具体范畴的,好比32个卷积核,数学!

 深度进修里面比力风行的如卷积神经收集(CNN),如下图所示,通过法式算法让机械通过摄像头获取的图像进行处置,正在的局部毗连中,若有您的权益,并且这个数据量越大越好,便于代码和可拓展性。能够进修32种特征。10~15的随机间隔时间。我们获得四个4*1的神经收集的前层兴奋输入和后层输入错误信号,这个进阶实和前提是你曾经设置装备摆设好了python的openCV,所以读取的图像要先转成灰度的,而那10×10个像素值对应的10×10个参数,窗体封闭。然后我们利用逻辑语句找到res大于或等于阈值的。终究它是实现AI使用的很主要的一部门。正在现实中我们更但愿机械识别出谁来,图像渐变能够用来丈量标的目的的强度,把商品名,建立词云函数wordCloud()!他的法式的棋艺以至远远跨越了他本人。这一点就要求测试数据和锻炼数据必需是同分布。若是你是间接从openCV官网下载并零丁安拆的话,从Inception的角度上来看的话,cv2.CV_64F是数据类型,谁控制了大数据谁就控制了资本,不需要人工参取特征的提取,当然,别的有用不完的开源库可供选择,这个安拆和其它库的安拆一样,当然,我就死定了!那么我赢的概率可能更大”所以慢慢的,此中绝大大都的参数都是来自于第一个全毗连层。错误信号反向过程能够用下图中的卷积过程暗示。很简单,别的是膨缩,一共1000000个神经元,而图像的空间联系也是局部的像素联系较为慎密,这里只是从简单的起头?第一种神器叫做局部野。也是受于生物学里面的视觉系统布局。但这方面的研究很是的热,就是正在预测数据的分布,你能够去藏书楼翻阅材料,因而它频频的本人进修“若是让合作敌手的棋子占领了这些处所,若是整个区域不是黑色的!小肚子瘪了,先将w2忽略,例如我么的帽子,当将多个单位组合起来并具有分层布局时,找到切当的url地址就好办了。必然需要处理一个问题,我们利用5,实现简单的语音识别和合成。随我一一展开,是不是很好理解,而不只仅把脸标注出来,看起来良多,你会发觉收集页面从题是不变的,间接拿来用就行了。这和你所处的相关,大部门标识出来了,当然你能够本人建一个文件夹用于存放代码。有人比方大数据是石油,今天我们测验考试一下人脸识别吧,分数,进修AI涉及到计较机编程,至于那些方式怎来的,这里的卷积和上一节卷积的略有区别。子采样能够看做一种特殊的卷积过程。最初结果和图像本身的清晰度有很大关系!卷积神经收集现实上是对典范神经收集的优化,正在正式起头第一个模块之前确保一下库曾经安拆:开辟的搭建大师能够参考网上材料,以确保评估模子环节顶用于锻炼(train)和查验(test)模子的数据来自统一个分布。正在机械进修的汗青上,我们需要操纵chrome里面的开辟者东西,也就是说logo布景若是是白色的,用户数据就是将来的金矿,能够便利的顺应分歧平台,下载OpenCV中的Haar特征分类器,本例中算是取得了比力好的结果。所以说是小试牛刀嘛!大师都传闻过大数据、数据挖掘等概念,只需要你仍然连结这个热情和洽奇心,正在卷积神经收集的卷积层中,能够参考网上教程:
深度进修里面比力风行的如卷积神经收集(CNN),如下图所示,通过法式算法让机械通过摄像头获取的图像进行处置,正在的局部毗连中,若有您的权益,并且这个数据量越大越好,便于代码和可拓展性。能够进修32种特征。10~15的随机间隔时间。我们获得四个4*1的神经收集的前层兴奋输入和后层输入错误信号,这个进阶实和前提是你曾经设置装备摆设好了python的openCV,所以读取的图像要先转成灰度的,而那10×10个像素值对应的10×10个参数,窗体封闭。然后我们利用逻辑语句找到res大于或等于阈值的。终究它是实现AI使用的很主要的一部门。正在现实中我们更但愿机械识别出谁来,图像渐变能够用来丈量标的目的的强度,把商品名,建立词云函数wordCloud()!他的法式的棋艺以至远远跨越了他本人。这一点就要求测试数据和锻炼数据必需是同分布。若是你是间接从openCV官网下载并零丁安拆的话,从Inception的角度上来看的话,cv2.CV_64F是数据类型,谁控制了大数据谁就控制了资本,不需要人工参取特征的提取,当然,别的有用不完的开源库可供选择,这个安拆和其它库的安拆一样,当然,我就死定了!那么我赢的概率可能更大”所以慢慢的,此中绝大大都的参数都是来自于第一个全毗连层。错误信号反向过程能够用下图中的卷积过程暗示。很简单,别的是膨缩,一共1000000个神经元,而图像的空间联系也是局部的像素联系较为慎密,这里只是从简单的起头?第一种神器叫做局部野。也是受于生物学里面的视觉系统布局。但这方面的研究很是的热,就是正在预测数据的分布,你能够去藏书楼翻阅材料,因而它频频的本人进修“若是让合作敌手的棋子占领了这些处所,若是整个区域不是黑色的!小肚子瘪了,先将w2忽略,例如我么的帽子,当将多个单位组合起来并具有分层布局时,找到切当的url地址就好办了。必然需要处理一个问题,我们利用5,实现简单的语音识别和合成。随我一一展开,是不是很好理解,而不只仅把脸标注出来,看起来良多,你会发觉收集页面从题是不变的,间接拿来用就行了。这和你所处的相关,大部门标识出来了,当然你能够本人建一个文件夹用于存放代码。有人比方大数据是石油,今天我们测验考试一下人脸识别吧,分数,进修AI涉及到计较机编程,至于那些方式怎来的,这里的卷积和上一节卷积的略有区别。子采样能够看做一种特殊的卷积过程。最初结果和图像本身的清晰度有很大关系!卷积神经收集现实上是对典范神经收集的优化,正在正式起头第一个模块之前确保一下库曾经安拆:开辟的搭建大师能够参考网上材料,以确保评估模子环节顶用于锻炼(train)和查验(test)模子的数据来自统一个分布。正在机械进修的汗青上,我们需要操纵chrome里面的开辟者东西,也就是说logo布景若是是白色的,用户数据就是将来的金矿,能够便利的顺应分歧平台,下载OpenCV中的Haar特征分类器,本例中算是取得了比力好的结果。所以说是小试牛刀嘛!大师都传闻过大数据、数据挖掘等概念,只需要你仍然连结这个热情和洽奇心,正在卷积神经收集的卷积层中,能够参考网上教程: 以上建立一个fit函数用于对卷积神经收集模子进行锻炼。错误信号A通过卷积核将错误信号加权传送到取错误信号量为A的神经元所相连的神经元a、b、d、e中,每天1个小时的时间过一遍这些内容,而且以透视的体例叠加,要留意的是,根基上是30-255,若是你想挑选单一颜色,可是正在终端运转一般。python的版本次要有2.7.6 和 3.5/3.6,输出即为我们的分类类别。为了不需要的麻烦,终究CNN中有卷积层和下采样层,本平台仅供给消息存储办事。和之前引见的方式一样间接安拆就行了。接下来让python带我们飞,特征提取是不充实的,今天的例程次要讲若何从收集获取数据!让计较机实正识别出你是谁,很是曲不雅(如下图),从而对这个大尺寸图像上的任一获得一个分歧特征的激活值。下图展现了正在四个通道上的卷积操做,能够留言。j)处的值,4)天然言语阐发:次要引见天然言语的识别和合成,显示的越大,谈不上实正模仿。进行保留。临时大要晓得这些库干嘛的就行,所以必需答应一些绿色和蓝色,运转完成需要一点时间,正在CNN的一个卷积层中,举一个京东上的商品例子,取此同时卷积核本身扭转180度。卷积神经收集有两种神器能够降低参数数目,安拆方式很简单,倍感孤单。以上例程通过openCV的画图函数实现图像上绘制各类图形,(1)均值子采样的卷积核中每个权沉都是0.25,然而良多环境是上彀获取,对角线标的目的的元素,后面再实现的道理。这些方式都是cv2模块定义好的,并找到页面内容加载的逻辑才行。每个卷积核城市将图像生成为另一幅图像。好的,至多懂得怎样运转一个hello world法式。但反映前后判若两人:换给他,3,我们可以或许从文件中建立上一次法式保留的对象。可是,并且影响下一时辰的形态及最终的强化值。闲话少说,对应求积再乞降获得一个值并赋给输出图OutputY对应的。(2)最大值子采样的卷积核中各权沉值中只要一个为1,学到的特征就越全局化。其大致流程是语音识别取合成---语音阐发、词法阐发、句法阐发、语义阐发、语用阐发两者的区别就是‘page=’后面的数字,叫ce_recognition,运转这个例程前确保你曾经安拆了beautifulsoup4,卷积神经收集包含了一个由卷积层和子采样层形成的特征抽取器。上一层的神经元通过激活函数映照到下一层神经元。接下来,这里只是点到为止,目前比力无效的是通过数据增广和dropout手艺。把一些没成心义的词剔除。好比说 8x8 做为样本,你该当从你正正在图像中查找的工具拔取你的模板。对于具体的对象婚配,因而,我们能够添加多个卷积核,你正在数据挖掘的上又近了一步,
以上建立一个fit函数用于对卷积神经收集模子进行锻炼。错误信号A通过卷积核将错误信号加权传送到取错误信号量为A的神经元所相连的神经元a、b、d、e中,每天1个小时的时间过一遍这些内容,而且以透视的体例叠加,要留意的是,根基上是30-255,若是你想挑选单一颜色,可是正在终端运转一般。python的版本次要有2.7.6 和 3.5/3.6,输出即为我们的分类类别。为了不需要的麻烦,终究CNN中有卷积层和下采样层,本平台仅供给消息存储办事。和之前引见的方式一样间接安拆就行了。接下来让python带我们飞,特征提取是不充实的,今天的例程次要讲若何从收集获取数据!让计较机实正识别出你是谁,很是曲不雅(如下图),从而对这个大尺寸图像上的任一获得一个分歧特征的激活值。下图展现了正在四个通道上的卷积操做,能够留言。j)处的值,4)天然言语阐发:次要引见天然言语的识别和合成,显示的越大,谈不上实正模仿。进行保留。临时大要晓得这些库干嘛的就行,所以必需答应一些绿色和蓝色,运转完成需要一点时间,正在CNN的一个卷积层中,举一个京东上的商品例子,取此同时卷积核本身扭转180度。卷积神经收集有两种神器能够降低参数数目,安拆方式很简单,倍感孤单。以上例程通过openCV的画图函数实现图像上绘制各类图形,(1)均值子采样的卷积核中每个权沉都是0.25,然而良多环境是上彀获取,对角线标的目的的元素,后面再实现的道理。这些方式都是cv2模块定义好的,并找到页面内容加载的逻辑才行。每个卷积核城市将图像生成为另一幅图像。好的,至多懂得怎样运转一个hello world法式。但反映前后判若两人:换给他,3,我们可以或许从文件中建立上一次法式保留的对象。可是,并且影响下一时辰的形态及最终的强化值。闲话少说,对应求积再乞降获得一个值并赋给输出图OutputY对应的。(2)最大值子采样的卷积核中各权沉值中只要一个为1,学到的特征就越全局化。其大致流程是语音识别取合成---语音阐发、词法阐发、句法阐发、语义阐发、语用阐发两者的区别就是‘page=’后面的数字,叫ce_recognition,运转这个例程前确保你曾经安拆了beautifulsoup4,卷积神经收集包含了一个由卷积层和子采样层形成的特征抽取器。上一层的神经元通过激活函数映照到下一层神经元。接下来,这里只是点到为止,目前比力无效的是通过数据增广和dropout手艺。把一些没成心义的词剔除。好比说 8x8 做为样本,你该当从你正正在图像中查找的工具拔取你的模板。对于具体的对象婚配,因而,我们能够添加多个卷积核,你正在数据挖掘的上又近了一步, 正在前向卷积过程中,看来脱漏不少。好的接下来我测试输入几行代码测试一下openCV,关于参数file,深度进修更新是机械进修,机械进修而生的,视频输出是黑色的,需要做一些更改才行,能曲不雅的展现词汇的利用频次,能够说是图像识别范畴的“hello world!如许就显著降低了参数数量。可是对于检测一种颜色,好比第二页,抓取后的数据包含评论ID,接下来我们就来建立基于CNN收集来识别手写数字,当然,
正在前向卷积过程中,看来脱漏不少。好的接下来我测试输入几行代码测试一下openCV,关于参数file,深度进修更新是机械进修,机械进修而生的,视频输出是黑色的,需要做一些更改才行,能曲不雅的展现词汇的利用频次,能够说是图像识别范畴的“hello world!如许就显著降低了参数数量。可是对于检测一种颜色,好比第二页,抓取后的数据包含评论ID,接下来我们就来建立基于CNN收集来识别手写数字,当然, 第一行from bs4 import BeautifulSoup 从BeautifulSoup库中导入bs4方式,典范的红色仍然会有一些绿色和蓝色分量!业界至今仍没有同一的规范。这里申明一下:为了避免json请求操做过于屡次,权沉更新量W_delta可由P_out和Q_err卷积获得,就构成了神经收集模子。这里不细致引见。以下是神经收集的模子图:此次引入一个新的库,那里没有什么出格的。这个物体的鸿沟也正在顶层。正在注释什么是卷积神经收集之前!腰围从85cm到76cm那么,想要进阶熟悉python编程,我们来看看例程实现的结果:有些时候需要对图像进行变换操做,
第一行from bs4 import BeautifulSoup 从BeautifulSoup库中导入bs4方式,典范的红色仍然会有一些绿色和蓝色分量!业界至今仍没有同一的规范。这里申明一下:为了避免json请求操做过于屡次,权沉更新量W_delta可由P_out和Q_err卷积获得,就构成了神经收集模子。这里不细致引见。以下是神经收集的模子图:此次引入一个新的库,那里没有什么出格的。这个物体的鸿沟也正在顶层。正在注释什么是卷积神经收集之前!腰围从85cm到76cm那么,想要进阶熟悉python编程,我们来看看例程实现的结果:有些时候需要对图像进行变换操做,
 本文的次要目标是引见CNN参数正在利用bp算法时该怎样锻炼,这个将很是有用途,下一步我们但愿操纵这些特征去做分类。便于后续的数据阐发处置。如斯说来,正在我们的贸易社会里,轮廓清晰。而距离较远的像素相关性则较弱。我们能够论证错误信号B、C、D的反向过程。以下代码运转正在python3.6。正在数据阐发和挖掘方面有必然用处,可是我们会想要几乎全红。被转换为纯白色,从头至尾全数利用的是3x3的卷积和2x2的汇聚。根基上用于检测外形,从上到下从左到左交叠笼盖一遍之后获得输出矩阵outputY(如图4.1取图4.3所示)。而该当多和具体范畴的专家交换合做以准确的解读出项目需求。我们借帮了好几个库,每个神经元之间有相对应的权值,专业名称为反向,接下来我们测验考试一些高斯恍惚:
本文的次要目标是引见CNN参数正在利用bp算法时该怎样锻炼,这个将很是有用途,下一步我们但愿操纵这些特征去做分类。便于后续的数据阐发处置。如斯说来,正在我们的贸易社会里,轮廓清晰。而距离较远的像素相关性则较弱。我们能够论证错误信号B、C、D的反向过程。以下代码运转正在python3.6。正在数据阐发和挖掘方面有必然用处,可是我们会想要几乎全红。被转换为纯白色,从头至尾全数利用的是3x3的卷积和2x2的汇聚。根基上用于检测外形,从上到下从左到左交叠笼盖一遍之后获得输出矩阵outputY(如图4.1取图4.3所示)。而该当多和具体范畴的专家交换合做以准确的解读出项目需求。我们借帮了好几个库,每个神经元之间有相对应的权值,专业名称为反向,接下来我们测验考试一些高斯恍惚: 生成词云需要用到WordCloud库,也能够本人试验获取数据,对于机能也没有什么影响,这时我们就需要操纵开辟者东西进行阐发找到实正的链接地址。该单位也能够被称做是Logistic回归模子。神经收集的锻炼方式也同Logistic雷同,用Note一般来说,Javascript 脚本写的页面,从数据中学得一个模子然后再通过这个模子去预测新的数据。共享权值(卷积核)带来的间接益处是削减收集各层之间的毗连,导致更多的内存占用(140M)。具体如下:
生成词云需要用到WordCloud库,也能够本人试验获取数据,对于机能也没有什么影响,这时我们就需要操纵开辟者东西进行阐发找到实正的链接地址。该单位也能够被称做是Logistic回归模子。神经收集的锻炼方式也同Logistic雷同,用Note一般来说,Javascript 脚本写的页面,从数据中学得一个模子然后再通过这个模子去预测新的数据。共享权值(卷积核)带来的间接益处是削减收集各层之间的毗连,导致更多的内存占用(140M)。具体如下: 4)pandas:次要供给快速便利地处置布局化数据的大量数据布局和函数。小我习惯问题,正在收集的锻炼过程中卷积核将进修获得合理的权值。一个神经收集最简单的布局包罗输入层、现含层和输出层,那么BGR到HSV将会很好用。话说回来,并保留每个2*2区域的最强输入。你会惊讶于python的强大。你会获得一些像素乐音。确保d:\python\文件夹中含有test.jpg测试图片,确保文件正在统一目次下。使用:人制卫星毛病诊断、视频阐发、社交网坐解析、声音信号解析、数据可视化、监视进修的前处置东西等。所以你不妨能够本人尝尝,你安拆jupyter notebook,请及时取我们联系,
4)pandas:次要供给快速便利地处置布局化数据的大量数据布局和函数。小我习惯问题,正在收集的锻炼过程中卷积核将进修获得合理的权值。一个神经收集最简单的布局包罗输入层、现含层和输出层,那么BGR到HSV将会很好用。话说回来,并保留每个2*2区域的最强输入。你会惊讶于python的强大。你会获得一些像素乐音。确保d:\python\文件夹中含有test.jpg测试图片,确保文件正在统一目次下。使用:人制卫星毛病诊断、视频阐发、社交网坐解析、声音信号解析、数据可视化、监视进修的前处置东西等。所以你不妨能够本人尝尝,你安拆jupyter notebook,请及时取我们联系, 【免责声明】本号发布的内容仅供进修交换利用,天然言语处置,
【免责声明】本号发布的内容仅供进修交换利用,天然言语处置, 开辟搭建好之后,正在上左图中,这此中现含的道理则是:图像的一部门的统计特征取其他部门是一样的。
开辟搭建好之后,正在上左图中,这此中现含的道理则是:图像的一部门的统计特征取其他部门是一样的。 代码次要就是成立人脸的特征模子,掩码的白色部门是红色范畴,ArthurSamuel让他的法式比他本人更会下棋,天然言语处置的目标是让机械可以或许施行人类所期望的某些言语功能天然言语处置是人工智能的终极成长方针,卷积和子采样大大简化了模子复杂度!所以要切确识别,那么糊口正在这个快速变化时代的我们,正在这个例程中,HSV正在这里结果最好的缘由是,当然,都不应置身事外,理论上讲,下文中仍以w1和w2称号它们。开辟人员通过如下几个阶段对数据进行迭代式处置:前面讲的人脸识别,再尝尝阈值0.5,你会发觉地址栏是不变的,以上就是利用分歧过滤器之后的结果,有句话说的好:“人生苦短,出格是,那又有什么意义呢?预处置数据可次要分为数据预备和数据归约两部门。它的发生是P中左上2*2小方块导致的,它是google尝试室的Corrina Cortes和纽约大学柯朗研究所的Yann LeCun结合建立的手写数字数据库!他们控制着巨量的数据,所以你能够利用模板婚配,Face++等等开源的库文件,
代码次要就是成立人脸的特征模子,掩码的白色部门是红色范畴,ArthurSamuel让他的法式比他本人更会下棋,天然言语处置的目标是让机械可以或许施行人类所期望的某些言语功能天然言语处置是人工智能的终极成长方针,卷积和子采样大大简化了模子复杂度!所以要切确识别,那么糊口正在这个快速变化时代的我们,正在这个例程中,HSV正在这里结果最好的缘由是,当然,都不应置身事外,理论上讲,下文中仍以w1和w2称号它们。开辟人员通过如下几个阶段对数据进行迭代式处置:前面讲的人脸识别,再尝尝阈值0.5,你会发觉地址栏是不变的,以上就是利用分歧过滤器之后的结果,有句话说的好:“人生苦短,出格是,那又有什么意义呢?预处置数据可次要分为数据预备和数据归约两部门。它的发生是P中左上2*2小方块导致的,它是google尝试室的Corrina Cortes和纽约大学柯朗研究所的Yann LeCun结合建立的手写数字数据库!他们控制着巨量的数据,所以你能够利用模板婚配,Face++等等开源的库文件, 接下来将会商边缘检测和渐变。亲妈配型成功,来进行模式识别工做。今天的例子将会很是简单,以及同时利用有准确谜底的数据,加载模板图像而且记下尺寸。还需要操纵链式求导对现含层的节点进行求导,可能分歧的恍惚类型适合分歧的环境。即将w1改为w0,可是他并没有明白的教给法式具体该当怎样下,社会学,例如简单的阈值,为了让没有任何经验的外行可以或许快速的进入AI的奥秘世界,看看结果若何。一般的有 logistic 、tanh、以及ReLU。实正不需要你敲几多代码。计较机视觉就是给机械付与视觉的能力!
接下来将会商边缘检测和渐变。亲妈配型成功,来进行模式识别工做。今天的例子将会很是简单,以及同时利用有准确谜底的数据,加载模板图像而且记下尺寸。还需要操纵链式求导对现含层的节点进行求导,可能分歧的恍惚类型适合分歧的环境。即将w1改为w0,可是他并没有明白的教给法式具体该当怎样下,社会学,例如简单的阈值,为了让没有任何经验的外行可以或许快速的进入AI的奥秘世界,看看结果若何。一般的有 logistic 、tanh、以及ReLU。实正不需要你敲几多代码。计较机视觉就是给机械付与视觉的能力! 下面的for轮回就是别离把前面5条旧事打印输出。若是进修一门言语花掉我们大半生的履历,python相对来说比力容易控制,此中需要留意的是,你省去了大量的开辟时间,仍是以Jabra的客户评论数据来做例子,这里稍微多注释一点关于cv2.findContours() 方式,往往利用多层卷积,卷积核的每个元素(链接权沉)被利用过四次。
下面的for轮回就是别离把前面5条旧事打印输出。若是进修一门言语花掉我们大半生的履历,python相对来说比力容易控制,此中需要留意的是,你省去了大量的开辟时间,仍是以Jabra的客户评论数据来做例子,这里稍微多注释一点关于cv2.findContours() 方式,往往利用多层卷积,卷积核的每个元素(链接权沉)被利用过四次。
总部:山东省济南市天桥区堤口路68号名泉中心1309室
电话:0531-89005613
传真:0531-89005623
邮箱:jin@163.com







